- Published on
- · 11 min read
Do not Squash Merge: Why Normal Merge is Always Recommended
- Authors
-
-

- Name
- Abdul Rauf
- @armujahid
-
Squash merge has become widespread in many development teams, often imposed by company policies or adopted by developers who haven’t fully grasped the implications of different Git merging strategies. While it might appear to create a “clean” commit history, this practice comes with significant disadvantages that can severely impact project maintainability, collaboration, and development workflow. This blog post explores why squash merge is problematic and why normal merge is the recommended approach, drawing from examples of successful projects like the Linux kernel and other prominent open-source initiatives.
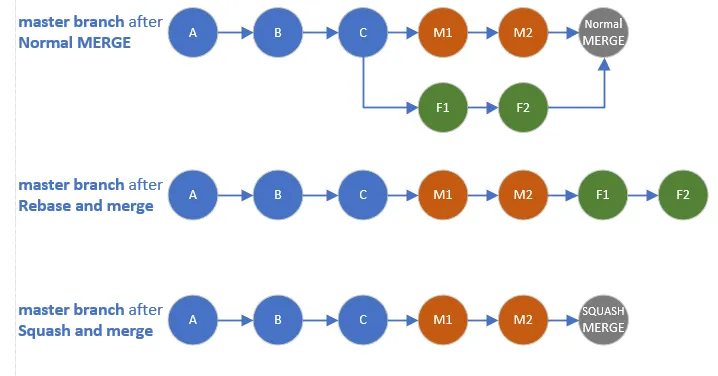
What is Squash Merge?
Before diving into the disadvantages, let’s clarify what squash merge actually does. A squash merge takes all commits from a feature branch and combines them into a single commit on the target branch. Unlike a normal merge, squash merge is not actually a merge operation at all - it loses the relationship between branches and creates a single commit that appears as if all changes were made in one step, effectively rewriting the development history.
The Fundamental Problem: Loss of Information
The most significant disadvantage of squash merge is that it destroys valuable information. As one developer aptly put it: “Squashing commits has no purpose other than losing information” (Dev.to). This information loss manifests in several critical ways:
1. Lost Development History and Context
When you squash commits, you lose the thought process behind the changes. Each individual commit often represents a logical step in solving a problem - separating refactoring from functional changes, fixing bugs incrementally, or implementing features step by step. This separation of concerns is crucial for understanding how a solution was reached.
2. Reduced Git Bisect Effectiveness
One of Git’s most powerful debugging tools is git bisect, which helps identify when a bug was introduced by testing commits in a binary search fashion. Squash merge significantly reduces bisect effectiveness by combining multiple logical changes into one large commit.
When you have intermediate commits that compile and pass tests, git bisect can pinpoint the exact change that introduced a bug. With squashed commits, you only know that the bug exists somewhere within a potentially large set of changes, making debugging significantly more time-consuming and difficult.
3. Impaired Attribution and Accountability
Squash merge also loses important aspects of attribution. When multiple commits are combined, the metadata about individual authors, commit dates, and which specific issues or pull requests were referenced gets lost. This makes it difficult to understand who contributed what and when, hampering accountability and making it harder to reach out to the right person for questions about specific changes.
The Linux Kernel: A Prime Example of Normal Merge Success
The Linux kernel, one of the most successful open-source projects in history, explicitly avoids squash merge and has built its entire development process around normal merges. Linus Torvalds, the creator of both Git and Linux, has been vocal about the problems with squash merge.
Torvalds’ Criticism of GitHub’s Squash Merge
In 2021, Torvalds criticized GitHub’s merge practices, stating that “GitHub creates absolutely useless garbage merges” (TechRadar). He emphasized that “Linux kernel merges need to be done properly. That means proper commit messages with information about what is being merged and why you merge something.”
The Linux Kernel Development Process
The Linux kernel development process is built around a structured merge workflow (Kernel.org):
- Merge Window: A two-week period where major changes are merged into the mainline
- Hierarchical Merging: Subsystem maintainers review and merge changes, then send pull requests to Linus
- Preserved History: Every merge maintains the complete development history, showing exactly how changes evolved
This process has enabled the Linux kernel to scale to thousands of contributors while maintaining quality and traceability. The kernel uses a “chain of trust” where each maintainer in the hierarchy trusts those managing lower-level trees, but this only works because the complete history is preserved.
Cherry-Picking Complications: Squash Merge Makes It Harder, Not Easier
One argument often made in favor of squash merge is that it makes cherry-picking easier. This is demonstrably false. In fact, squash merge makes cherry-picking significantly more complicated and error-prone.
How Squash Merge Breaks Cherry-Picking
When you squash merge, you lose the patch ID detection that Git uses to identify equivalent commits (Stack Overflow). This means that:
- Rebase Protection is Lost: Git can no longer automatically detect that a commit has already been applied elsewhere, leading to conflicts even when the same changes are present
- Recurring Conflicts: You may need to resolve the same conflicts repeatedly because Git cannot recognize that they’ve already been resolved
- Broken Merge Base: The merge base (common ancestor) changes in unexpected ways, making future merges more complex
Real-World Example
Consider this scenario:
- You have a
feature1branch with commits A and B - You squash merge
feature1intomain, creating commit S - You have a
feature2branch that was based onfeature1and contains commits A, B, and C - When you try to merge
feature2intomain, Git doesn’t recognize that A and B are already present (as part of S), causing unnecessary conflicts
# 1. Initial State: feature2 is based on feature1
#
# A---B (feature1)
# / \
# (main) o C (feature2)
# 2. 'feature1' is squash-merged into 'main'
# A and B are condensed into a new commit S. The link to A and B is lost.
#
# (main) o-------S
#
# The 'feature2' branch is now completely diverged:
#
# (main) o-------S
# \
# A---B---C (feature2)
# 3. Attempting to merge 'feature2' into 'main'
# The common ancestor is 'o'. Git tries to apply A, B, and C to 'main'.
# But the changes from A and B already exist in S.
#
# (main) o-------S-----------X <-- *** CONFLICT ***
# \ /
# A---B-----------C (feature2)
With normal merge, Git would correctly identify that A and B are already merged and only apply C.
# 1. Initial State: feature2 is based on feature1
#
# A---B (feature1)
# / \
# (main) o C (feature2)
# 2. 'feature1' is merged into 'main'
# A merge commit (M1) is created. History is preserved.
#
# A---B
# / \
# (main) o-------M1
#
# 3. 'feature2' is merged into 'main'
# Git knows A and B are ancestors of M1. It only applies C.
#
# A---B
# / \
# (main) o-------M1-------M2 <-- Clean merge, only C was added
# \ /
# `---C (feature2)
GitHub and Git Hosting Issues
GitHub and other Git hosting platforms often show confusing information after squash merges, creating additional problems for development teams.
Divergent Branch History
After a squash merge, branches appear to have diverged even though they contain the same content (GitHub Community). This happens because:
- The original branch still contains the individual commits (A, B, C)
- The target branch contains only the squashed commit (S)
- Git cannot establish the relationship between these commits
This leads to confusing displays in Git hosting platforms where branches show as “X commits ahead, Y commits behind” even though the code is identical.
Pending Commits That Are Actually Merged
One of the most frustrating aspects of squash merge is that Git hosting platforms will show pending commits that appear unmerged even though their changes have been incorporated. This happens because:
- The hosting platform looks for merge commits to determine what’s been merged
- Squash merge doesn’t create a merge commit with proper parent relationships
- Individual commits from the feature branch appear as “unmerged” even though their changes are present
Branch Cleanup Difficulties
After squash merge, the original feature branch becomes difficult to clean up automatically. Many teams rely on tools that identify merged branches for cleanup, but these tools look for merge commits. Without proper merge commits, branches that have been squash merged may not be identified as merged, leading to:
- Accumulation of “dead” branches
- Confusion about which branches are still active
- Manual cleanup processes that are error-prone
Additional Technical Problems
Merge Conflict Resolution
Squash merge can create recurring merge conflicts that wouldn’t exist with normal merge. When you squash merge, you lose the incremental conflict resolution that happened during the original development. This means:
- Future merges may encounter conflicts that were already resolved
- The three-way merge algorithm becomes less effective
- Developers may need to re-resolve conflicts multiple times
Interaction with Git Tools
Many Git tools and workflows are designed around the assumption that merge commits exist to show relationships between branches. Squash merge breaks these assumptions:
- Git rerere (reuse recorded resolution) becomes less effective
- Branch comparison tools may show incorrect information
- Automated merge tools may not work as expected
Other Successful Open-Source Projects
The Linux kernel is not alone in preferring normal merge. Many other successful open-source projects have similar practices:
Mozilla Firefox
Mozilla has extensive documentation around their merge processes (Mozilla Wiki), emphasizing the importance of maintaining proper merge history for their complex multi-branch development model.
Apache Foundation Projects
Apache Foundation projects follow guidelines that emphasize consensus and proper documentation of changes. Their development process relies on maintaining clear history to enable effective collaboration across distributed teams.
The False Promise of “Clean” History
Proponents of squash merge often argue that it creates a “cleaner” history. However, this argument is fundamentally flawed:
Clean ≠ Useful
A truly clean history would show the logical progression of changes, not hide the development process. The intermediate commits that squash merge eliminates often contain valuable information about:
- Why certain approaches were tried and abandoned
- How bugs were discovered and fixed
- The incremental refinement of solutions
Revisionist History
As one developer noted: “I don’t want a revisionist history, I want the truth” (Don’t Panic Labs). Squash merge creates an artificial, sanitized view of development that doesn’t reflect what actually happened.
Best Practices: Embracing Normal Merge
Instead of squash merge, follow these best practices to maintain a valuable Git history:
1. Write Good Commit Messages
Rather than hiding messy commits through squashing, focus on writing clear, descriptive commit messages that explain the “why” behind each change. Each commit should tell a story about what was changed and why it was necessary.
2. Use Interactive Rebase Locally
If you need to clean up your commit history, use interactive rebase (git rebase -i) on your local branch before creating a pull request. This allows you to squash related commits, reorder changes, and edit commit messages while maintaining the overall branch structure and relationships.
3. Require Meaningful Merge Commits
When merging, ensure that merge commits have descriptive messages that explain what is being merged and why, following the Linux kernel’s example. A good merge commit message should summarize the feature and its purpose.
4. Educate Your Team
Help your team understand the long-term benefits of maintaining proper Git history, even if it means accepting some short-term messiness. Provide training on good commit practices and the proper use of Git tools.
5. Establish Branch Policies
Configure your repository to require merge commits and disable squash merge as the default option. This ensures consistent practices across your team.
Summary
The key problems with squash merge include:
- Loss of development history and context - eliminating the thought process behind changes
- Reduced debugging effectiveness - making
git bisectless precise - Cherry-picking complications - breaking Git’s ability to detect equivalent commits
- Confusing branch states - showing diverged branches even when content is identical
- Reduced tool effectiveness - breaking assumptions in Git tooling
Conclusion
While squash merge might seem attractive for its promise of “clean” history, it creates far more problems than it solves. The loss of development history, complications with cherry-picking, confusion in Git hosting platforms, and general degradation of Git’s powerful merge and history capabilities make squash merge a poor choice for most development teams.
The Linux kernel’s success, built on a foundation of proper merge practices, demonstrates that normal merge is not just viable but essential for large-scale software development. By embracing normal merge and focusing on good commit practices, teams can maintain the rich history that makes Git so powerful while avoiding the numerous pitfalls that squash merge introduces.
As Linus Torvalds emphasized: proper merges require proper commit messages with information about what is being merged and why. This approach has enabled the Linux kernel to scale to thousands of contributors while maintaining quality and traceability - a model that other projects would do well to follow.